publicfinalclassString implementsjava.io.Serializable, Comparable<String>, CharSequence{ /** The value is used for character storage. */ privatefinalchar value[]; }
public String substring(int beginIndex){ if (beginIndex < 0) { thrownew StringIndexOutOfBoundsException(beginIndex); } int subLen = value.length - beginIndex; if (subLen < 0) { thrownew StringIndexOutOfBoundsException(subLen); } return (beginIndex == 0) ? this : new String(value, beginIndex, subLen); }
public String concat(String str){ int otherLen = str.length(); if (otherLen == 0) { returnthis; } int len = value.length; char buf[] = Arrays.copyOf(value, len + otherLen); str.getChars(buf, len); returnnew String(buf, true); }
public String replace(char oldChar, char newChar){ if (oldChar != newChar) { int len = value.length; int i = -1; char[] val = value; /* avoid getfield opcode */
while (++i < len) { if (val[i] == oldChar) { break; } } if (i < len) { char buf[] = newchar[len]; for (int j = 0; j < i; j++) { buf[j] = val[j]; } while (i < len) { char c = val[i]; buf[i] = (c == oldChar) ? newChar : c; i++; } returnnew String(buf, true); } } returnthis; }
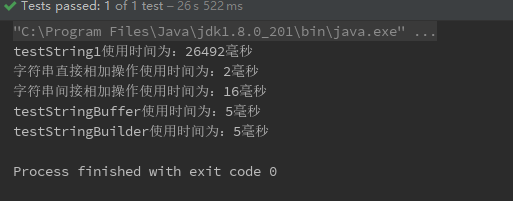
publicstaticvoidtestString1(){ String s = ""; long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { s += "weison"; } long end = System.currentTimeMillis(); System.out.println("testString1使用时间为:" + (end - start) + "毫秒"); }
publicstaticvoidtestStringBuffer(){ StringBuffer sb = new StringBuffer(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { sb.append("weison"); } long end = System.currentTimeMillis(); System.out.println("testStringBuffer使用时间为:" + (end - start) + "毫秒"); }
publicstaticvoidtestStringBuilder(){ StringBuilder sb = new StringBuilder(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { sb.append("weison"); } long end = System.currentTimeMillis(); System.out.println("testStringBuilder使用时间为:" + (end - start) + "毫秒"); }
publicstaticvoidtestString2(){ long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String s = "I"+"am"+"weison"; } long end = System.currentTimeMillis(); System.out.println("字符串直接相加操作使用时间为:" + (end - start) + "毫秒"); } publicstaticvoidtestString3(){ String s1 = "I"; String s2 = "am"; String s3 = "weison"; long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { String s = s1 + s2 + s3; } long end = System.currentTimeMillis(); System.out.println("字符串间接相加操作使用时间为:" + (end - start) + "毫秒"); }
}
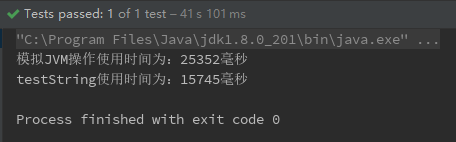
测试结果 :
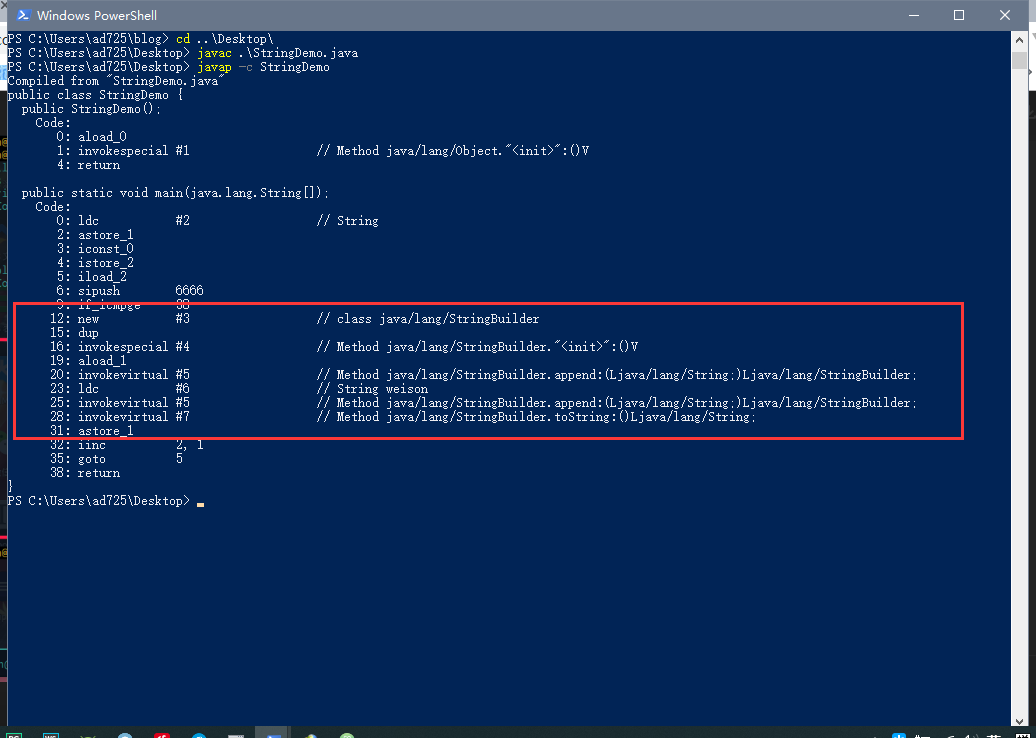
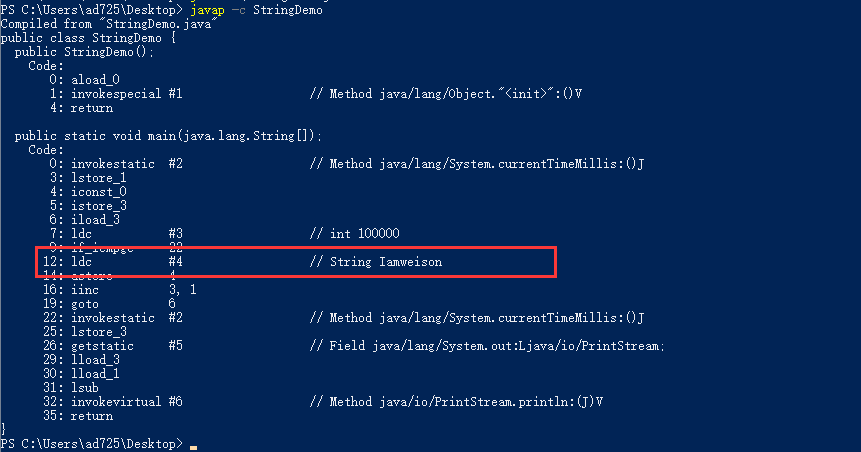
在最开始的反编译解析中 , 有说过 s += "weison"; , JVM会自动优化 , 我们来看看下面这段代码:
publicstaticvoidmain(String[] args){ testString1(); testString(); } publicstaticvoidtestString1(){ String s = ""; long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { s += "weison"; } long end = System.currentTimeMillis(); System.out.println("testString1使用时间为:" + (end - start) + "毫秒"); }
publicstaticvoidtestString(){ String s = ""; long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) { StringBuilder sb = new StringBuilder(s); sb.append("weison"); s=sb.toString(); } long end = System.currentTimeMillis(); System.out.println("模拟jvm优化操作使用时间为:" + (end - start) + "毫秒"); } }